Sure Chet, thanks for your interest...
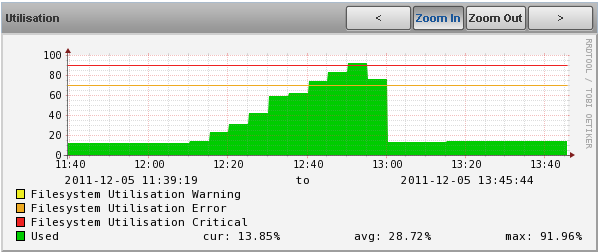
This is based on the standard Filesystem monitoring template applied to /Server, polling OID 1.3.6.1.2.1.25.2.3.1.6 to get a value for usedBlocks.
I had a requierment to be able to set custom thresholds for ever filesystem on every server. Creating local template copies for this would be a mess, so I have a slightly more complex setup to determine my Critical, Error and Warning thresholds. For each server I have 3 Custom Properties, (each shown with examples):
cFilesystemCritical: '/|95 /boot|80 /home|95 /opt|95 /tmp|90 /var|90'
cFilesystemError: '/|90 /boot|70 /home|90 /opt|90 /tmp|80 /var|80'
cFilesystemWarning: '/|85 /boot|60 /home|95 /opt|95 /tmp|70 /var|70'
I then use a one-liner in the 'Maximum Value' field of each threshold to dynamically obtain the threshold for that filesystem like so, (for the Critical threshold):
here.totalBlocks * float(here.device().getProperty('cFilesystemCritical').strip().split(here.name())[1].split()[0].split('|')[1]) / 100
A little complicated, but it has worked fine for a long time and continues to raise timely filesystem utilisation threshold breach events across many servers on a daily basis.
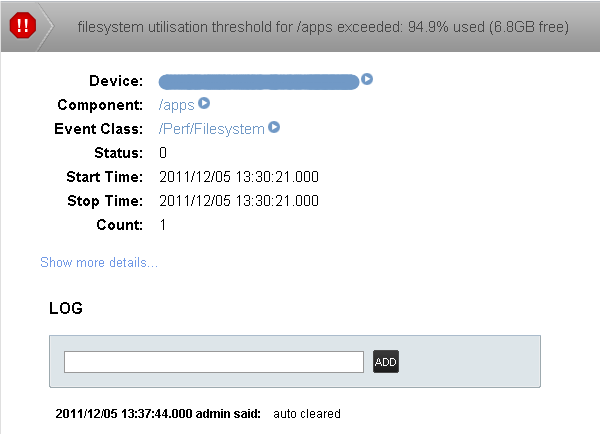
In the case above, it seems there was a delay somewhere in the chain of:
snmp poll->snmp value returned->threshold applied->event raised
As the filesytem utilisation was graphed and there were no errors in the zenperfsnmp log, I can only assume that the snmp poll returned data in a timely fashion. This leads me to believe that the delay occured the processing the obtained value. However 40 mins between threshold breach and event raising seem very strange...
Any ideas/help would be greatly appreciated...
J.