
Aug 12, 2010 3:05 AM
Remote interface graph draw wrong values if snmp cicle have a high value
-
Like (0)
Hi,
it's a problem i've had in 2.5.2 too but i never understand what was due to.
this is my problem
this graph is taken form a server that i reach on vpn ipsec
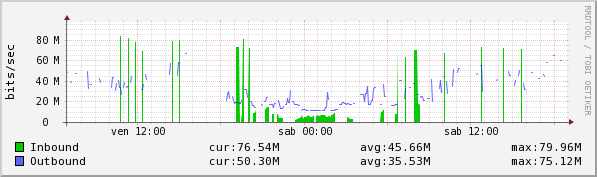
1- there's a lof of gaps between value (while i never loose ping)
2- value is wrong... this interface has a constant flow of 300mbits (it's a tvcc server)
i see that if i look in a local server (on zenoss lan)
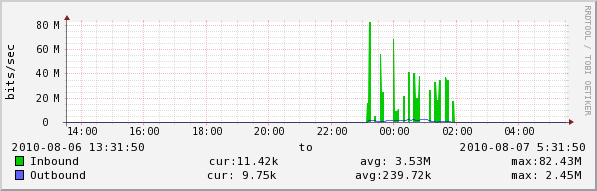
both server has a giga interface so it's not a 32 or 64 bit counter (i check the 64bit oid and i've no reply to snmp v2 query).
so what's the problem?
i see that interface graph datasource have a "derive" value... the problem can be that the remote data collection is too slow and interface graph make a derive value between an high value (300) and a zero value and give me this strage graph?
i'm sure of effective network usage because windows server task manager tell me that giga interface is used at 35%
i hope someone can give me a hint to understand where's the problem.
Thanks
Andrea Consadori
I would check the zenperfsnmp.log and make sure this device is not occasionally timing out.
1- i can confirm that is not a remote connection issue because on the same customer this is the interface switch port graph where the server is connected
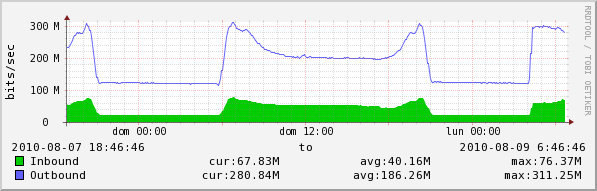
2- every remote device under /server i've give me interface graph issue (both linux nas and windows server)
3- only switch that use ethernetCsmacd_64 report correct graph
i try ethernetCsmacd_64 oid on server but they doesn't work with this mib... (so i cannot use this template on serve interface)
look here, changing SNMP Performance Cycle Interval (secs) from default to 60 on collector the problem disappear

and datapoint rate grow up
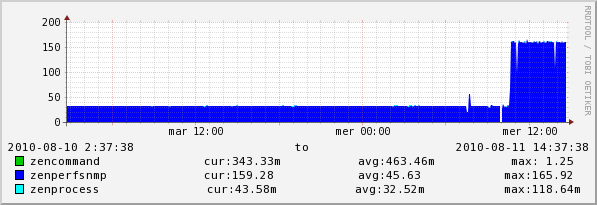
do you know why?
and look what happen if i set snmp perf cicle to 30 sec
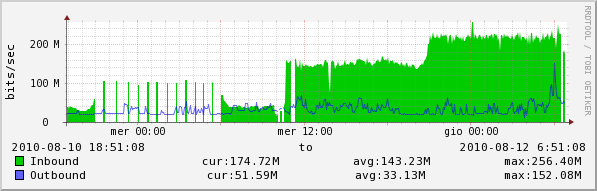
until 11.00 is with snmp perf cicle with default value
between 11.00 and 18.00 is with 60 sec
after 18.00 (of mer) is with snmp circle to 30 sec...
and the same on performance collector
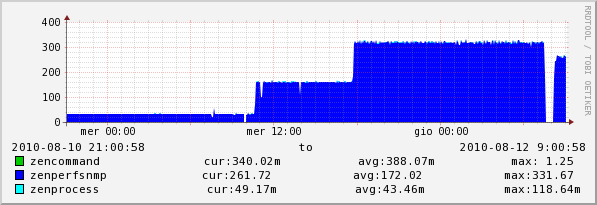
noone have a reply to this issue?or if someone can confirm me that's an issue i open a ticket (but maybe there's another explaination)
Hey Andrea,
I had the same issue... Since I wanted a little more detail on my graphs anyway, I just lowered the SNMP cycle to 60secs...
I also compared the RRD creation from Cacti for my interfaces on the same device and noticed that Cacti uses COUNTER and sets the MAX value for the datasource... Zenoss was not setting MAX and was using DERIVE... I don't know if it's related but in Zenoss my graphs were getting weird when the traffic was above 100Mbits... It was like they were losing a zero... They were going back to 10Mbits every time they were above 100... COUNTER and MAX fixed that...
I also changed the "Default RRD create command" to the :
Hi, my issue is that i've 400 monitored device and if i lower snmp cicle to 60 i fix window server snmp polling but after some days zenperfsnmp daemon start to give a lot of traceback error and stop working.. if i set 120 second i've gaps in graphs but zenperfsnmp doesn't crash...
anyone can help?
note: this issue is only on remove (over vpn) windows server.. local windows server give no performance reporting issue...
maybe a zenoss-windows guru can help us to understand better what's going..
I am monitoring my my cisco switches that are on the same lan as the zenoss server. I have zenoss running in a virtual machine and i can see the graph issues.
see : thread/14490?tstart=0
How can i adjust SNMP polling times ? im not too familiar with it.
Thank you
how many device do you have under monitor?
be aware of this change, can brake all other perf graph (reverting value fix the issue if happen)
Advanced - Collectors - localhost (your collector) - edit - and change "SNMP Performance Cycle Interval (secs)"
here i found an usefoul post that explain why setting snmp cycle to 60sec fix the issue
|
Follow Us On Twitter »
|
Latest from the Zenoss Blog » |

|
Community | Products | Services Resources | Customers Partners | About Us | |
|
|
|
Copyright © 2005-2011 Zenoss, Inc.
|
||||||

